
GASでスクレイピングを行いたい場合、正規表現を用いて文字列を抽出するのが基本です。
ただ、正規表現を使うのはちょっと面倒な部分もあるので、良いライブラリはないかなと探していたところ、見つけたライブラリが「Parser」というライブラリです。
Parserライブラリ
Google Developer Expertの方が作成されたものです。
英語ですが、以下の記事がありました。
https://www.kutil.org/2016/01/easy-data-scrapping-with-google-apps.html
ライブラリを追加する
ライブラリを追加するには、GASエディタにてIDを指定します。
上記の記事には以下のようにライブラリのIDが記載してありますが、2021年2月現在の旧エディタのものです。
Create a new Google Apps Script and insert a new library (Resources -> Library)
M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV
2021年2月現在、GASのエディタは以下のような新しいものに変わっています。
ライブラリを追加するには、左側のライブラリの部分から追加するのですが、上記のライブラリIDを入力しても追加できませんでした。
GASのエディタが新しくなったことにより、ライブラリID(GASのプロジェクトID)が変更になったようですね。
Parserライブラリはプロジェクトが公開されていたので、以下のURLから開くと、新しいライブラリIDを確認することができました。
新しいライブラリIDは以下の通りです。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNwこのIDを入力することで、ライブラリに追加できます。
Parserライブラリの使い方
上記の記事にも使用方法の記載がありますが、fromText、toTextの2つのパラメータを指定して、指定された範囲の文字列を抜き出すという仕組みのようです。
例えば、
<title>サイトのタイトル</title>
というタイトルを抜き出したい場合、
fromTextに<title>
toTextに</title>
を指定すると、「サイトのタイトル」という文字列が抜き出せるということです。
実際にスクレイピングしてみる
僕は競馬が好きなので、JRAのホームページを対象にスクレイピングしてみます。
2021年2月7日(日)のレース情報が記載されています。
https://www.jra.go.jp/keiba/calendar2021/2021/2/0207.html
コードは以下の通りです。
function getRaceFromCalendar() {
var response = UrlFetchApp.fetch("https://www.jra.go.jp/keiba/calendar2021/2021/2/0207.html");
var content = response.getContentText("SJIS");
var venues = Parser.data(content).from('<table class="basic narrow-xy">').to('</table>').iterate();
for (var index = 0; index < venues.length; index++) {
var venue = venues[index];
Logger.log(Parser.data(venue).from('<div class="main">').to('</div>').build());
}
}2行目で対象のURLを読み込みます。
JRAのページはSJISでエンコードされているので、3行目でSJISを指定して、レスポンスからHTMLコンテンツを取得します。
4行目がParserライブラリを使用している箇所です。
レース情報のページのうち、以下の部分がtableタグで作成されているので、そのtableタグを抜き出します。
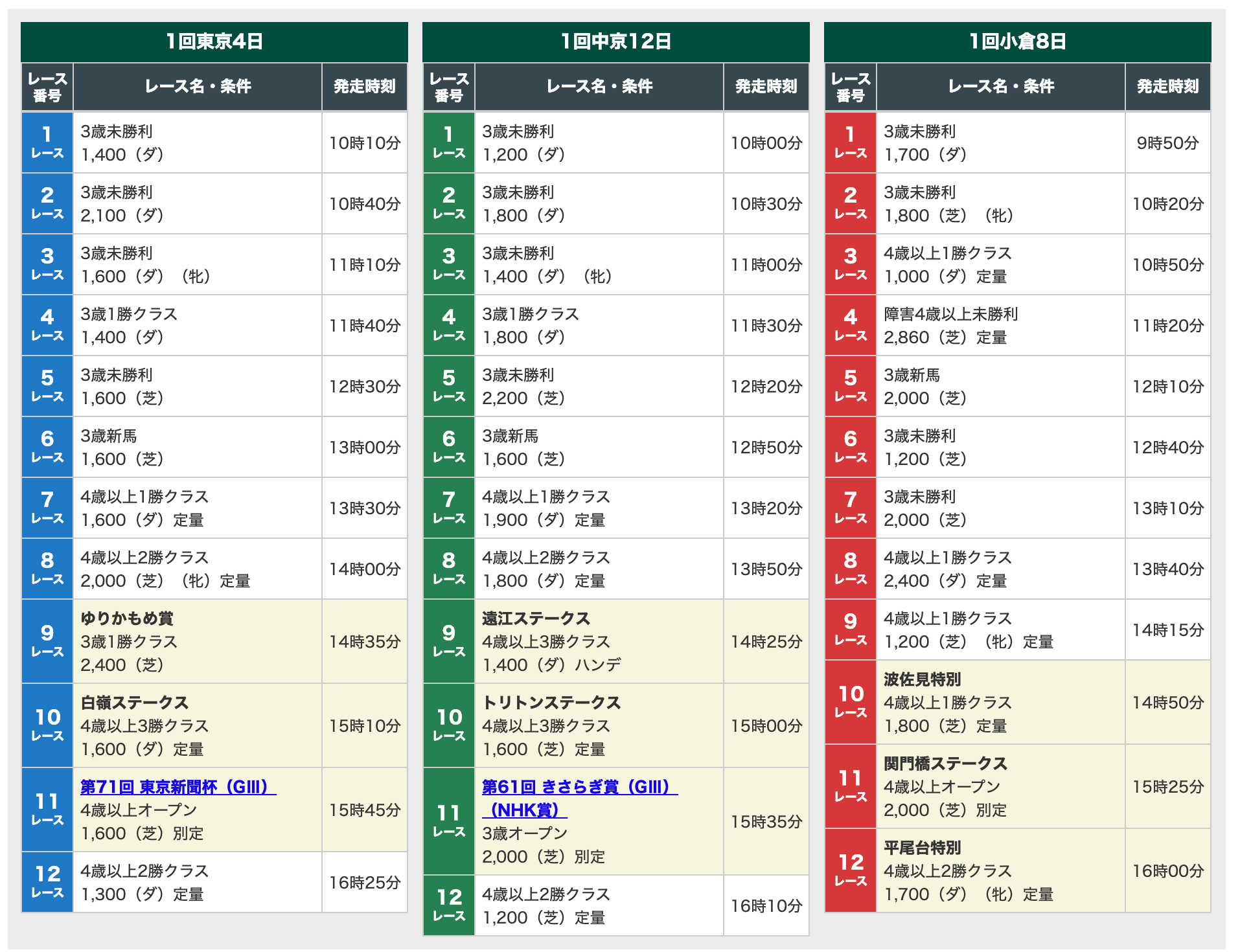
fromTextに <table class=”basic narrow-xy”>
toTextに</table>
と指定することで、tableタグの中身を取得できます。
該当部分は以下のようにtableタグになっています。
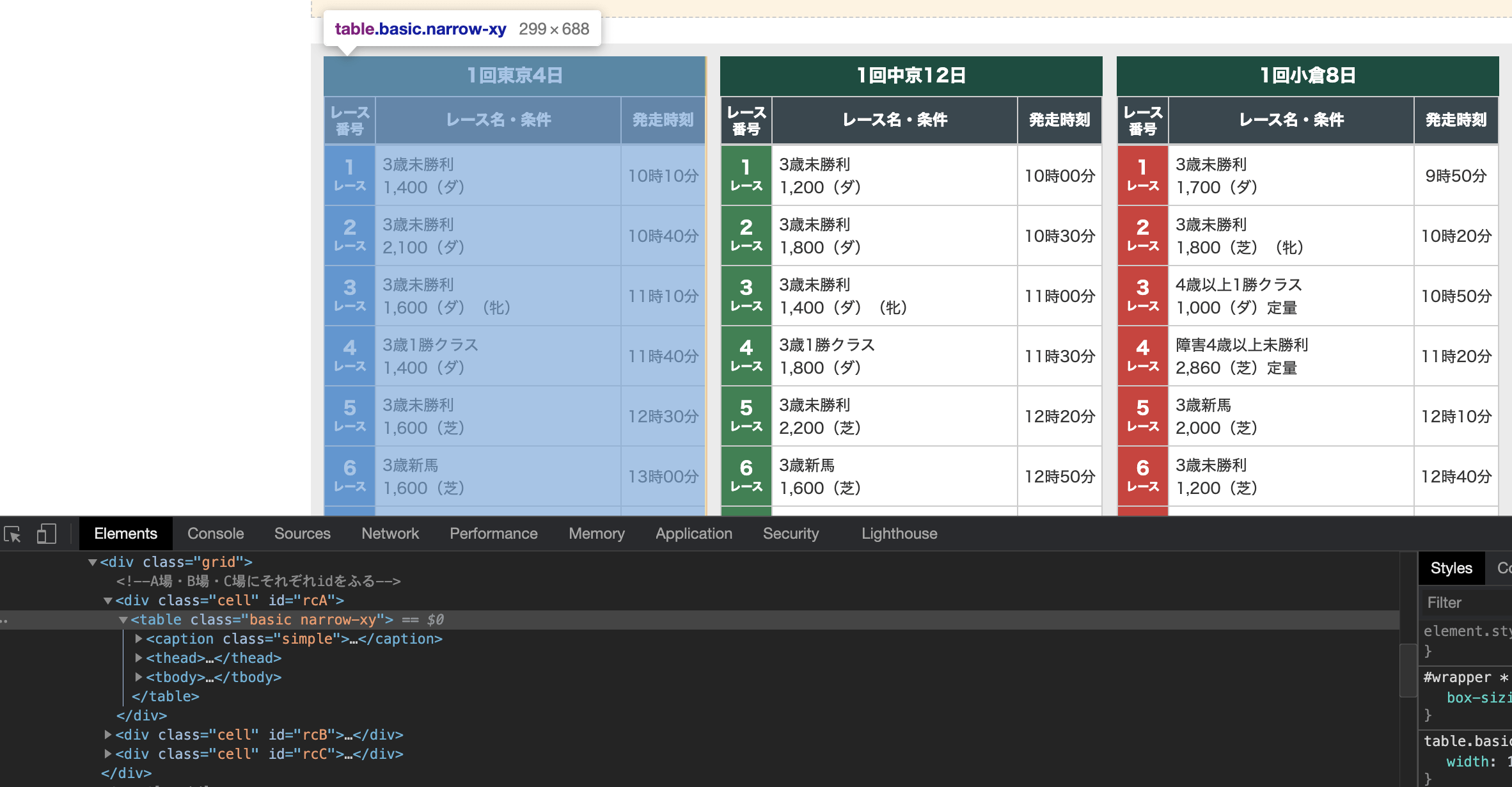
また、iterate()という関数を使用すると、該当する箇所を全て取得できます。
今回の例だと、東京、中京、小倉、それぞれ1レースから12レースで1つのtableタグになっていて、上記のようなtableタグは3箇所あるので、3つ全て取得できます。
6行目がtableタグごとのループ、つまり今回だと3回繰り返します。
7行目がtableタグ1つ分の取得、iterate()で取得すると配列の形式になっているので、indexを使用して順番に取り出しています。
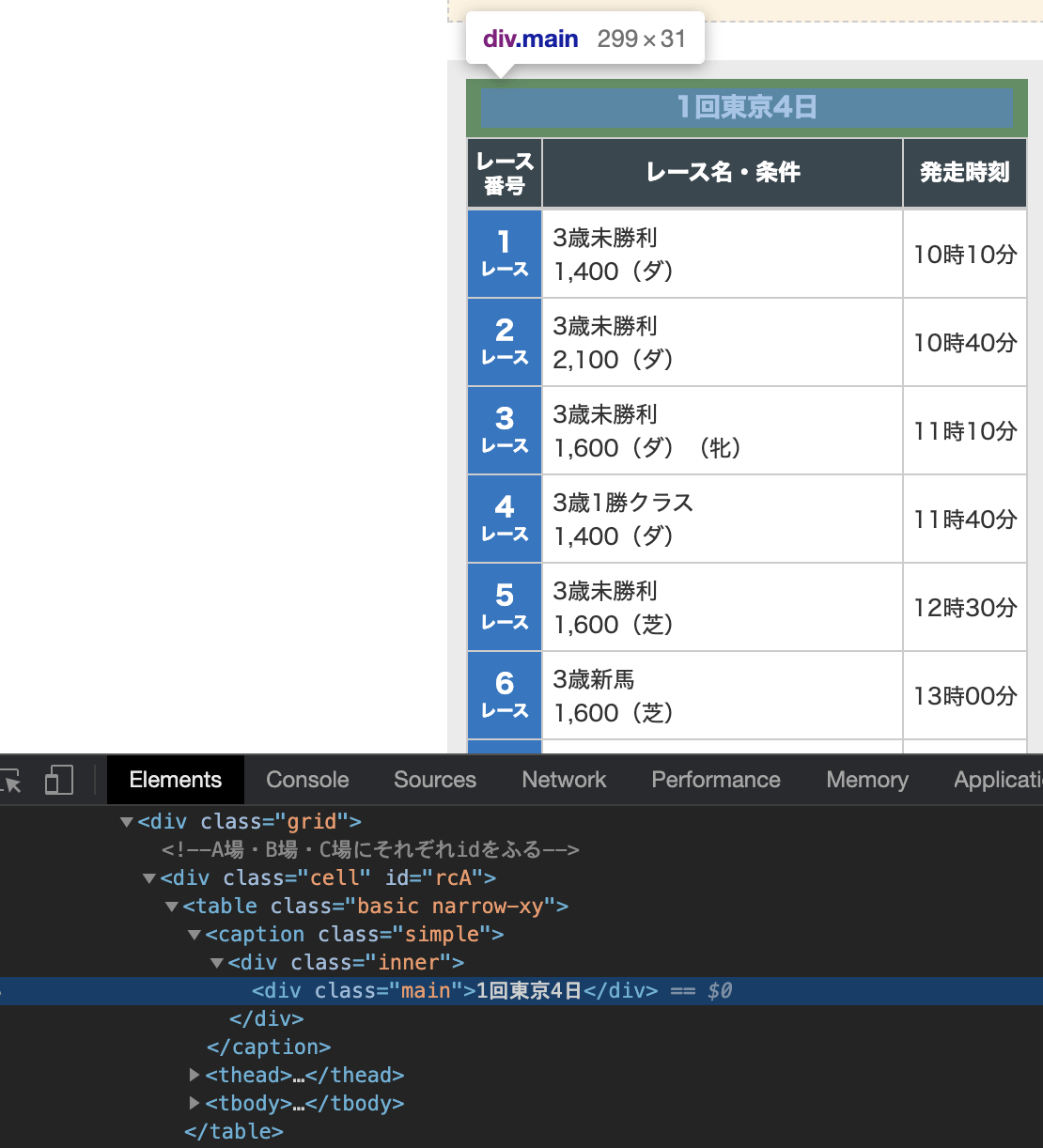
9行目では、tableタグから「1回東京4日」の部分を抜き出しています。
該当箇所は以下のように、<div class=”main”>とdivタグで囲われていることが分かります。
9行目では、build()という関数を使用しています。
これは先ほどのiterate()と違って、該当箇所を1箇所だけ抜き出す関数です。
該当箇所が1箇所だけで複数抜き出す必要がない場合は、build()の方を使用します。
今回の例では、6行目でループしているので、tableタグごとに、この処理を3回繰り返すことになります。
実行すると結果は以下のようになります。
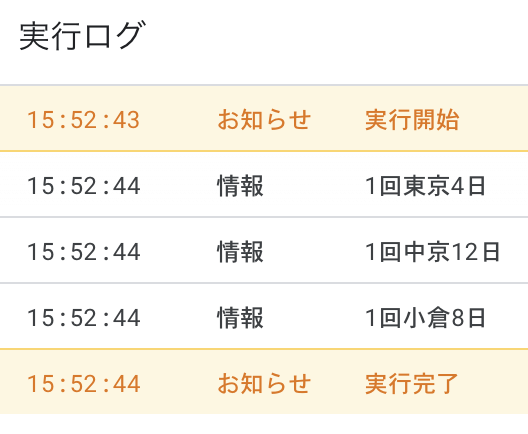
tableタグのヘッダー部分にある文字列を抜き出すことができました。
同様に、自分がどの情報を抜き出したいかによって、コードで指定するfromText、toTextの部分を書き換えます。
例えば、レースの名前を抜き出したい場合は以下のようにします。
Logger.log(Parser.data(venue).from('<p class="race_class">').to('</p>').iterate());実行すると結果は以下のようになります。

レースの距離の部分を抜き出したい場合は以下のようになります。
Logger.log(Parser.data(venue).from('<span class="dist">').to('</span>').iterate());実行すると結果は以下のようになります。

このように、from〜toを指定して要素を抽出できる場合は、Parserライブラリを使用すると簡単にスクレイピングできると思うので、オススメです。


コメント
情報、ありがとうございます。
でも、
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
のIDの部分がコピーできなくて、つらいです。
コメントいただき、ありがとうございます。
コピーできるように変更しました。